ApacheDrillを使ってjsonをSQLのように扱う
サーバーから出されたログを後で集計していろいろと解析したい場合というのはよくあることだと思います。その場合に、なにかしらのNoSQLにぶち込んでおけば大丈夫ではあるんですが、NoSQLを用意するまでもない、サービス的にログを貯めるためだけにNoSQLを用意するのが厳しい、そこまでやりたくない。そういった場合にApacheDrillを使うという方法があります。
ApacheDrillとは
ApacheDrillというのは
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage
というやつで、BigDataの分析とかで使うようなものです。
ビックデータって言ってもうちのサービスそんなにデータないよ? いえいえ、必ずしもビックデータで使わなくてもApacheDrillというのは非常に便利なツールです。
ApacheDrillは通常なにかしらの言語&パーサーをつかって解析して集計などしなくてはいけない部分を、SQLで簡単に扱えるようにしてくれるツールなのです。
ApacheDrillのインストール
どうやら現在は1.6がリリースされているようなので公式からダウンロードしてください。Drillの動作には、Java1.7またはJava1.8が必要です。(最近のmacの人はだいたい入ってる)今回は、コマンドラインから使うだけなので、
ダウンロード→解凍 で終わりです。
実際に使ってみる
サンプル用のjsonを用意しました。こちらからダウンロードしてください。
では実際にjsonを分析していきます。
drillを起動する
$ ./apache-drill-1.6.0/bin/drill-embedded

セレクトしてみる (*)
select * from dfs.`/Users/nori/ApacheDrillSample/sample.json`;
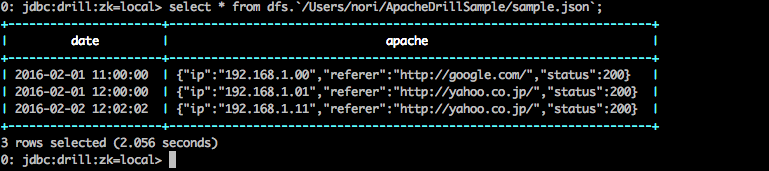
通常のSQLと同じようにSELECT 文でデータを取得しています。(データが大きい場合*だとコケることがありますので注意)
FROMの部分ですが、 dfs. というのはシステムのパス(この場合自分が使っているmacのパス)だよということを表しています。
ApacheDrillではほかに、cp,hbase,hive,mongoなどがあります。
- cp・・・Points to JAR files in the Drill classpath, such as employee.json that you can query.
- dfs・・・Points to the local file system, but you can configure this storage plugin to point to any distributed file system, such as a Hadoop or S3 file system.
- hbase・・・Provides a connection to HBase.
- hive・・・Integrates Drill with the Hive metadata abstraction of files, HBase, and libraries to read data and operate on SerDes and UDFs.
- mongo・・・Provides a connection to MongoDB data.
条件つけてセレクトする( where)
select `date` from dfs.`/Users/nori/ApacheDrillSample/sample.json` where `date` < '2016-02-02';

ApacheDrillでは、DataTypeとして、INT, VARCHAR,DATEなどサポートされています。 型変換やタイムスタンプなどでうまくいかない時はドキュメントを参照した方がいいです。
jSONの中身にたいしてクエリを投げる
上のようなやつだと、 apacheの中に、ip, referer, status などが入っていて役に立ちません。 そこで、それらにアクセスするようにします。
select * from dfs.`/Users/nori/ApacheDrillSample/sample.json` d where d.`apache`.`referer` LIKE '%yahoo%';

こんなかんじで apache.refererにもwhere したり出来ます。
セレクト結果をDumpする
ちょっと面倒です。
上の結果を、csvで出力したいとすると以下のようになります。
use dfs.tmp; alter session set `store.format`='csv'; create table dfs.tmp.my_output as select * from dfs.`/Users/nori/ApacheDrillSample/sample.json` d where d.`apache`.`referer` LIKE '%yahoo%';
ローカルのシステムの/tmpを使うことを宣言。
出力フォーマットとして、 csvを設定。
そこに my_outputとして、先ほどのセレクトの結果をぶち込みます。
終わるとき
!q